오픈AI, 상시학습 체제 가동
사전 훈련 방식에서 탈피해
현실에서 인간이 공부하듯
AI가 실시간 데이터 학습
AGI 핵심 단계 진입 평가
AI 통제 어려워질 우려도
텍사스에 건설 중인 오픈AI 스타게이트 프로젝트를 위한 데이터센터.오픈AI
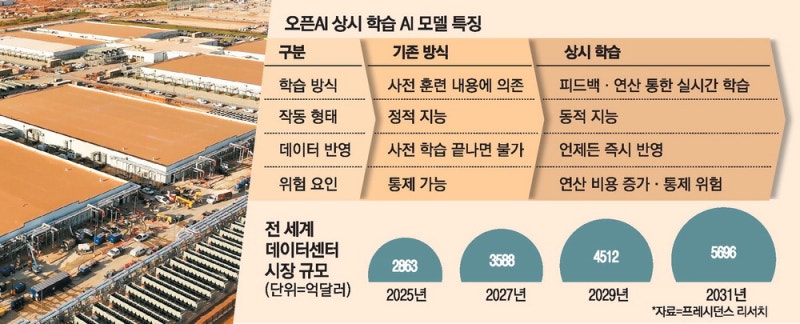
오픈AI가 인공지능(AI) 모델을 '상시 학습형'으로 운영하는 새로운 훈련 방식을 본격 가동하고 있다. 기존처럼 사전 훈련을 마친 뒤 학습을 멈추는 구조가 아니라, 사용자 피드백과 실시간 연산을 통해 모델이 끊임없이 스스로 개선되는 형태다. 이는 샘 올트먼 오픈AI 최고경영자(CEO)가 이야기한 '범용 AI(AGI)'를 향한 과정으로, AI가 한 번의 훈련으로 완성되는 정적인 존재가 아니라 현실 속 피드백을 통해 마치 인간처럼 스스로 진화하는 동적 지능으로 나아가고 있음을 보여준다.
피터 호셸레 오픈AI 스타게이트 총괄은 최근 미국 라스베이거스에서 개최된 오라클 AI 월드 2025 행사에 참여해 "이제 훈련과 추론을 구분할 필요가 없어졌다"며 "모델이 끊임없이 실행되고 샘플링과 훈련을 반복하며 실시간으로 더 똑똑해지는 새로운 체제로 진입했다"고 말했다. AI가 대규모 사전 학습을 마친 뒤 사용자 질의에 응답해왔던 기존 구조에서 벗어나 응답 단계에서도 추가 연산을 수행하면서 스스로 성능을 개선하는 '테스트 타임 컴퓨트' 개념을 본격화한 것이다. 호셸레 총괄은 "모델이 단지 응답만 하는 게 아니라 추론 중에도 더 많은 계산 자원을 사용해 스스로 개선된다"고 설명했다.
IT 전문매체 더 인포메이션에 따르면 오픈AI는 이미 1년 전 첫 추론 모델을 출시한 이후 테스트 타임 컴퓨트를 연습해왔다. 여기에 인간의 피드백을 반영하는 '강화학습' 기술까지 결합하고 있다. 사용자가 챗GPT 답변에 '좋아요'나 '싫어요'를 표시하는 것도 모델이 실시간으로 학습하는 데이터로 쓰인다. 이는 강화학습과 추론의 경계를 허물면서 AI가 실제 환경 속에서 진화하도록 만든다.
이러한 변화는 오픈AI가 그동안 예고해왔던 '지속적 학습' 개념이 현실화하고 있음을 보여준다. 올트먼 CEO는 지난 8월 GPT-5 출시 전날 열린 기자간담회에서 "GPT-5는 아직 완전한 AGI라 보긴 어렵다"며 "가장 큰 이유는 이 모델이 배포 이후에도 새로운 정보를 받아들이고 학습하는 능력, 즉 지속적 학습을 하지 못하기 때문"이라고 말한 바 있다. 그러면서 그는 "진정한 AGI에는 이러한 능력이 반드시 포함돼야 한다"고 강조했다. 결국 이번에 드러난 오픈AI의 상시 학습 구조는 올트먼 CEO가 언급한 AGI의 핵심 조건이 실험적 형태로 구현되기 시작한 단계로 볼 수 있다. AI가 인간의 피드백을 학습하며 점점 더 현실 적응적 판단을 수행하는 방향으로 바뀌고 있다는 점에서 오픈AI가 AGI의 문턱에 한 걸음 더 다가섰다는 평가가 나온다.
다만 이러한 상시 학습 구조는 응답 단계에서 추가 연산이 이뤄지는 만큼 칩 사용량이 대폭 증가할 뿐 아니라 AI의 안전성과 통제력 유지도 어려워질 수 있다는 단점이 존재한다. AI가 스스로 학습을 반복하면 인간이 설정한 방향에서 벗어나거나 자체적인 판단 체계를 형성할 수 있기 때문이다.
이 같은 우려에도 오픈AI가 상시 학습 개념을 도입한 것은 AI 모델의 근본적 기능을 강화하기 위한 시도로 풀이된다. 오픈AI 공동창업자 안드레이 카르파티는 최근 팟캐스트 '드워케시 쇼'에 출연해 "현재의 AI 에이전트는 아직 충분히 지능적이지 않다"며 "완전한 형태로 작동하려면 약 10년은 더 걸릴 것"이라고 내다봤다. 그는 또 "지금의 AI는 인간의 감독 없이는 제대로 기능하지 못하는 수준"이라고 지적했다.
[실리콘밸리 원호섭 특파원]
사전 훈련 방식에서 탈피해
현실에서 인간이 공부하듯
AI가 실시간 데이터 학습
AGI 핵심 단계 진입 평가
AI 통제 어려워질 우려도
오픈AI가 인공지능(AI) 모델을 '상시 학습형'으로 운영하는 새로운 훈련 방식을 본격 가동하고 있다. 기존처럼 사전 훈련을 마친 뒤 학습을 멈추는 구조가 아니라, 사용자 피드백과 실시간 연산을 통해 모델이 끊임없이 스스로 개선되는 형태다. 이는 샘 올트먼 오픈AI 최고경영자(CEO)가 이야기한 '범용 AI(AGI)'를 향한 과정으로, AI가 한 번의 훈련으로 완성되는 정적인 존재가 아니라 현실 속 피드백을 통해 마치 인간처럼 스스로 진화하는 동적 지능으로 나아가고 있음을 보여준다.
피터 호셸레 오픈AI 스타게이트 총괄은 최근 미국 라스베이거스에서 개최된 오라클 AI 월드 2025 행사에 참여해 "이제 훈련과 추론을 구분할 필요가 없어졌다"며 "모델이 끊임없이 실행되고 샘플링과 훈련을 반복하며 실시간으로 더 똑똑해지는 새로운 체제로 진입했다"고 말했다. AI가 대규모 사전 학습을 마친 뒤 사용자 질의에 응답해왔던 기존 구조에서 벗어나 응답 단계에서도 추가 연산을 수행하면서 스스로 성능을 개선하는 '테스트 타임 컴퓨트' 개념을 본격화한 것이다. 호셸레 총괄은 "모델이 단지 응답만 하는 게 아니라 추론 중에도 더 많은 계산 자원을 사용해 스스로 개선된다"고 설명했다.
IT 전문매체 더 인포메이션에 따르면 오픈AI는 이미 1년 전 첫 추론 모델을 출시한 이후 테스트 타임 컴퓨트를 연습해왔다. 여기에 인간의 피드백을 반영하는 '강화학습' 기술까지 결합하고 있다. 사용자가 챗GPT 답변에 '좋아요'나 '싫어요'를 표시하는 것도 모델이 실시간으로 학습하는 데이터로 쓰인다. 이는 강화학습과 추론의 경계를 허물면서 AI가 실제 환경 속에서 진화하도록 만든다.
이러한 변화는 오픈AI가 그동안 예고해왔던 '지속적 학습' 개념이 현실화하고 있음을 보여준다. 올트먼 CEO는 지난 8월 GPT-5 출시 전날 열린 기자간담회에서 "GPT-5는 아직 완전한 AGI라 보긴 어렵다"며 "가장 큰 이유는 이 모델이 배포 이후에도 새로운 정보를 받아들이고 학습하는 능력, 즉 지속적 학습을 하지 못하기 때문"이라고 말한 바 있다. 그러면서 그는 "진정한 AGI에는 이러한 능력이 반드시 포함돼야 한다"고 강조했다. 결국 이번에 드러난 오픈AI의 상시 학습 구조는 올트먼 CEO가 언급한 AGI의 핵심 조건이 실험적 형태로 구현되기 시작한 단계로 볼 수 있다. AI가 인간의 피드백을 학습하며 점점 더 현실 적응적 판단을 수행하는 방향으로 바뀌고 있다는 점에서 오픈AI가 AGI의 문턱에 한 걸음 더 다가섰다는 평가가 나온다.
다만 이러한 상시 학습 구조는 응답 단계에서 추가 연산이 이뤄지는 만큼 칩 사용량이 대폭 증가할 뿐 아니라 AI의 안전성과 통제력 유지도 어려워질 수 있다는 단점이 존재한다. AI가 스스로 학습을 반복하면 인간이 설정한 방향에서 벗어나거나 자체적인 판단 체계를 형성할 수 있기 때문이다.
이 같은 우려에도 오픈AI가 상시 학습 개념을 도입한 것은 AI 모델의 근본적 기능을 강화하기 위한 시도로 풀이된다. 오픈AI 공동창업자 안드레이 카르파티는 최근 팟캐스트 '드워케시 쇼'에 출연해 "현재의 AI 에이전트는 아직 충분히 지능적이지 않다"며 "완전한 형태로 작동하려면 약 10년은 더 걸릴 것"이라고 내다봤다. 그는 또 "지금의 AI는 인간의 감독 없이는 제대로 기능하지 못하는 수준"이라고 지적했다.
[실리콘밸리 원호섭 특파원]
댓글목록
등록된 댓글이 없습니다.